This section explains Austral’s linear type system. We begin with the motivation: why do we need linear types? Then we explain what linear types are and how they solve our problems.
Resources and Lifecycles
Consider a file handling API:
type File;
function openFile(path: String): File;
function writeString(file: File, content: String): File;
function closeFile(file: File): Unit;
An experienced programmer understands the implicit lifecycle of the File
object:
- We create a
Filehandle by callingopenFile. - We write to the handle zero or more times.
- We close the file handle by calling
closeFile.
We can depict this graphically like this:

But, crucially: this lifecycle is not enforced by the compiler. There are a number of erroneous transitions that we don’t consider, but which are technically possible:

These fall into two categories:
-
Leaks: we can forget to call
closeFile, e.g.:let file: File = openFile("hello.txt"); writeString(file, "Hello, world!"); -- Forgot to close -
Use-After-Close: and we can call
writeStringon aFileobject that has already been closed:closeFile(file); writeString(file, "Goodbye, world!");And we can close the file handle after it has been closed:
closeFile(file); closeFile(file);
In a short linear program like this, we aren’t likely to make these mistakes. But when handles are stored in data structures and shuffled around, and the lifecycle calls are separated across time and space, these errors become more common.
And they don’t just apply to files. Consider a database access API:
type Db;
function connect(host: String): Db;
function query(db: Db, query: String): Rows;
function close(db: Db): Unit;
Again: after calling close we can still call query and close. And we can
also forget to call close at all.
And — crucially — consider this memory management API:
type Pointer<T>
Pointer<T> allocate(T value)
T load(Pointer<T> ptr)
void store(Pointer<T> ptr, T value)
void free(Pointer<T> ptr)
Here, again, we can forget to call free after allocating a pointer, we can
call free twice on the same pointer, and, more disastrously, we can call
load and store on a pointer that has been freed.
Everywhere we have resources — types with an associated lifecycle, where they must be created, used, and destroyed, in that order — we have the same kind of errors: forgetting to destroy a value, or using a value after it has been destroyed.
In the context of memory management, pointer lifecycle errors are so disastrous they have their own names:
Naturally, computer scientists have attempted to attack these problems. The traditional approach is called static analysis: a group of PhD’s will write a program that goes through the source code and performs various checks and finds places where these errors may occur.
Reams and reams of papers, conference proceedings, university slides, etc. have been written on the use of static analysis to catch these errors. But the problem with static analysis is threefold:
-
It is a moving target. While type systems are relatively fixed — i.e., the type checking rules are the same across language versions — static analyzers tend to change with each version, so that in each newer version of the software you get more and more sophisticated heuristics.
-
Like unit tests, it can usually show the presence of bugs, but not their absence. There may be false positives — code that is perfectly fine but that the static analyzer flags as incorrect — but more dangerous is the false negative, where the static analyzer returns an all clear on code that has a vulnerability.
-
Static analysis is an opaque pile of heuristics. Because the analyses are always changing, the programmer is not expected to develop a mental model of the static analyzer, and to write code with that model in mind. Instead, they are expected to write the code they usually write, then throw the static analyzer at it and hope for the best.
What we want is a way to solve these problems that is static and complete. Static in that it is a fixed set of rules that you can learn once and remember, like how a type system works. Complete in that is has no false negatives, and every lifecycle error is caught.
And, above all: we want it to be simple, so it can be wholly understood by the programmer working on it.
So, to summarize our requirements:
-
Correctness Requirement: We want a way to ensure that resources are used in the correct lifecycle.
-
Simplicity Requirement: We want that mechanism to be simple, that is, a programmer should be able to hold it in their head. This rules out complicated solutions involving theorem proving, SMT solvers, symbolic execution, etc.
-
Staticity Requirement: We want it to be a fixed set of rules and not an ever changing pile of heuristics.
All these goals are achievable: the solution is linear types.
What Linear Types Are
Let’s consider a linear file system API. We’ll use a vaguely C++ like syntax, but linear types are denoted by an exclamation mark after their name.
The API looks like this:
type File!;
function openFile(path: String): File!;
function writeString(file: File!, content: String): File!;
function closeFile(file: File!): Unit;
The openFile function is fairly normal: takes a path and returns a linear
File! object.
writeString is where things are different: it takes a linear File! object
(and consumes it), and a string, and it returns a “new” linear File!
object. “New” is in quotes because it is a fresh linear value only from the
perspective of the type system: it is still a handle to the same file. But don’t
think about the implementation too much: we’ll look into how this is implemented
later.
closeFile is the destructor for the File! type, and is the terminus of the
lifecycle graph: a File! enters and does not leave, and the object is disposed
of. Let’s see how linear types help us write safe code.
Can we leak a File! object? No:
let file: File! := openFile("sonnets.txt");
-- Do nothing.
The compiler will complain: the variable file is used zero
times. Alternatively:
let file: File! := openFile("sonnets.txt");
writeString(file, "Devouring Time, blunt thou the lion’s paws, ...");
The return value of writeString is a linear File! object, and it is being
silently discarded. The compiler will whine at us.
We can strike the “leak” transitions from the lifecycle graph:

Can we close a file twice? No:
let file: File! := openFile("test.txt");
closeFile(file);
closeFile(file);
The compiler will complain that you’re trying to use a linear variable twice. So we can strike the “double close” erroneous transition from the lifecycle graph:

And you can see where this is going. Can we write to a file after closing it? No:
let file: File! := openFile("test.txt");
closeFile(file);
let file2: File! := writeString(file, "Doing some mischief.");
The compiler will, again, complain that we’re consuming file twice. So we can strike the “use after close” transition from the lifecycle graph:
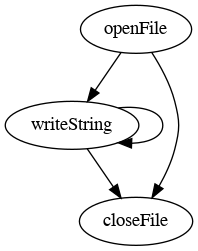
And we have come full circle: the lifecycle that the compiler enforces is exactly, one-to-one, the lifecycle that we intended.
There is, ultimately, one and only one way to use this API such that the compiler doesn’t complain:
let f: File! := openFile("rilke.txt");
let f_1: File! := writeString(f, "We cannot know his legendary head\n");
let f_2: File! := writeString(f_1, "with eyes like ripening fruit. And yet his torso\n");
...
let f_15: File! := writeString(f_14, "You must change your life.");
closeFile(f_15);
Note how the file value is “threaded” through the code, and each linear variable is used exactly once.
And now we are three for three with the requirements we outlined in the previous section:
-
Correctness Requirement: Is it correct? Yes: linear types allow us to define APIs in such a way that the compiler enforces the lifecycle perfectly.
-
Simplicity Requirement: Is it simple? Yes: the type system rules fit in a napkin. There’s no need to use an SMT solver, or to prove theorems about the code, or do symbolic execution and explore the state space of the program. The linearity checks are simple: we go over the code and count the number of times a variable appears, taking care to handle loops and
ifstatements correctly. And also we ensure that linear values can’t be discarded silently. -
Staticity Requirement: Is it an ever-growing, ever-changing pile of heuristics? No: it is a fixed set of rules. Learn it once and use it forever.
And does this solution generalize? Let’s consider a linear database API:
type Db!;
function connect(host: String): Db!;
function query(db: Db!, query: String): Pair[Db!, Rows];
function close(db: Db!) : Unit;
This one’s a bit more involved: the query function has to return a tuple
containing both the new Db! handle, and the result set.
Again: we can’t leak a database handle:
let db: Db! := connect("localhost");
-- Do nothing.
Because the compiler will point out that db is never consumed. We can’t close a database handle twice:
let db: Db! := connect("localhost");
close(db);
close(db); -- error: `db` consumed again.
Because db is used twice. Analogously, we can’t query a database once it’s closed:
let db: Db! := connect("localhost");
close(db);
let (db1, rows): Pair[Db!, Rows] := query(db, "SELECT ...");
close(db); -- error: `db` consumed again.
For the same reason. The only way to use the database correctly is:
let db: Db! := connect("localhost");
let (db1, rows): Pair[Db!, Rows] := query(db, "SELECT ...");
-- Iterate over the rows or some such.
close(db1);
What Linear Types Provide
Linear types give us the following benefits:
-
Manual memory management without memory leaks, use-after-
free, doublefreeerrors, garbage collection, or any runtime overhead in either time or space other than having an allocator available. -
More generally, we can manage any resource (file handles, socket handles, etc.) that has a lifecycle in a way that prevents:
- Forgetting to dispose of that resource (e.g.: leaving a file handle open).
- Disposing of the resource twice (e.g.: trying to free a pointer twice).
- Using that resource after it has been disposed of (e.g.: reading from a closed socket).
All of these errors are prevented statically, again without runtime overhead.
-
In-place optimization: the APIs we have looked at resemble functional code. We write code “as if” we were creating and returning new objects with each call, while doing extensive mutations under the hood. This gives us the benefits of functional programming (referential transparency and equational reasoning) with the performance of imperative code that mutates data wildly.
-
Safe concurrency. A value of a linear type, by definition, has only one owner: we cannot duplicate it, therefore, we cannot have multiple owners across threads. So imperative mutation is safe, since we know that no other thread can write to our linear value while we work with it.
-
Capability-based security: suppose we want to lock down access to the terminal. We want there to be only one thread that can write to the terminal at a time. Furthermore, code that wants to write to the terminal needs permission to do so.
We can do this with linear types, by having a linear
Terminaltype that represents the capability of using the terminal. Functions that read and write from and to the terminal need to take aTerminalinstance and return it. We’ll discuss capability based security in greater detail in a future section.